Kernel adaptive filter
Kernel adaptive filtering is an adaptive filtering technique for general nonlinear problems. It is a natural generalization of linear adaptive filtering in reproducing kernel Hilbert spaces. Kernel adaptive filters are online kernel methods, closely related to some artificial neural networks such as radial basis function networks and regularization networks. Some distinguishing features include: The learning process is online, the learning process is convex with no local minima, and the learning process requires moderate complexity.
Adaptive Filtering
A linear adaptive filter is a linear filter built on basic operational units like adders and multipliers and is usually implemented by programmable digital processors. Mathematically it can be modeled by a linear combiner 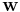 . Supplied with an input
. Supplied with an input 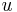 , the output of the filter is
, the output of the filter is 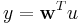 .
.
is also called the linear coefficients (weights) of the filter. The dimensionality of is the filter order. A unique feature of an adaptive filter is that its coefficient can be updated online according to some optimization criterion. One common criterion is to minimize the mean square error ![E [d- \mathbf{w} ^ {T} u]^2](/2012-wikipedia_en_all_nopic_01_2012/I/732ee402c33abb13927ec5a285aed6e7.png) . As you see, the adaptation of the weights is a supervised learning process, which requires training data
. As you see, the adaptation of the weights is a supervised learning process, which requires training data 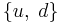 . The updating rule is
. The updating rule is
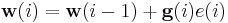
where 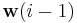 is the filter weight at time i-1. The error
is the filter weight at time i-1. The error 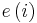 is the prediction error of on the i-th datum
is the prediction error of on the i-th datum 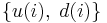
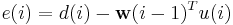
And 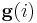 is the algorithm gain, which can assume different formats in different algorithms. The most notable adaptive filters include least mean squares filter and recursive least squares filter. Despite their simple structure (and probably because of it), they enjoy wide applicability and successes in diverse fields such as communications, control, radar, sonar, seismology, and biomedical engineering, among others. The theory of linear adaptive filters has reached a highly mature stage of development. However, the same can not be said about nonlinear adaptive filters.
is the algorithm gain, which can assume different formats in different algorithms. The most notable adaptive filters include least mean squares filter and recursive least squares filter. Despite their simple structure (and probably because of it), they enjoy wide applicability and successes in diverse fields such as communications, control, radar, sonar, seismology, and biomedical engineering, among others. The theory of linear adaptive filters has reached a highly mature stage of development. However, the same can not be said about nonlinear adaptive filters.
Adaptive Filtering in Reproducing Kernel Hilbert Spaces
Kernel adaptive filters are linear adaptive filters in reproducing kernel Hilbert spaces. They belong to a more general methodology called kernel methods. The main idea of kernel methods can be summarized as follows: transform the input data into a high-dimensional feature space via a positive definite kernel such that the inner product operation in the feature space can be computed efficiently through the kernel evaluation. Then appropriate linear methods are subsequently applied on the transformed data. As long as we can formulate the algorithm in terms of inner product (or equivalent kernel evaluation), we never explicitly have to compute in the high dimensional feature space. While this methodology is called kernel trick, we have to point out that the underlying reproducing kernel Hilbert space plays a central role to provide linearity, convexity, and universal approximation capability at the same time. Successful examples of this methodology include support vector machines, principal component analysis, Fisher discriminant analysis and many others.
Kernel adaptive filters include kernel least mean square, kernel affine projection algorithms, kernel recursive least squares, extended kernel recursive least squares and kernel Kalman filter. Viewed as a learning problem, kernel adaptive filters aim to estimate 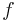 sequentially by minimizing
sequentially by minimizing ![E [d- f(u)]^2\,](/2012-wikipedia_en_all_nopic_01_2012/I/bedeaa37b75dfd90f7840271dd5a12e1.png) . The general updating rule of a kernel adaptive filter is
. The general updating rule of a kernel adaptive filter is
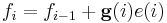
where 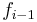 is the estimate at time
is the estimate at time 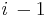 . is the prediction error of on the
. is the prediction error of on the 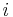 th datum.
th datum.
Kernel adaptive filters provide a new perspective for linear adaptive filters since linear adaptive filters become a special case being alternatively expressed in the dual space. Kernel adaptive filters clearly show that there is a growing memory structure embedded in the filter weights. They naturally create a growing radial basis function network, learning the network topology and adapting the free parameters directly from data at the same time. The learning rule is a beautiful combination of the error-correction and memory-based learning, and potentially it will have a deep impact on our understanding about the essence of learning theory.
References
- C. Richard, J. C. M. Bermudez, and P. Honeine. "Online prediction of time series data with kernels," IEEE Transactions on Signal Processing, 57(3):1058-1066, 2009.
- P. Bouboulis, S. Theodoridis “Extension of Wirtinger calculus and the complex kernel LMS”, IEEE Workshop on Machine Learning for Signal Processing, MLSP, Finland, 2010.
- K. Slavakis, S. Theodoridis, I Yamada, “Adaptive constrained learning in reproducing kernel Hilbert spaces”, IEEE Transactions on Signal Processing, pp. 4744-4764, Vol 57(12), 2009.
- K. Slavakis, S. Theodoridis, I. Yamada “Online classification using kernels and projection-based adaptive algorithms”, IEEE Transactions on Signal Processing, Vol. 56(7), pp. 2781-2797, 2008.
- K. Slavakis, S. Theodoridis “Sliding Window Generalized Kernel Affine Projection Algorithm using Projection Mappings”, Special Issue on Emerging Machine Learning Techniques in Signal Processing, EURASIP Journal on Advances in Signal Processing, vol. 2008, Article ID 830381, 2008. doi:10.1155/2008/830381.
- W. Liu, J. Principe, S. Haykin. Kernel Adaptive Filtering: A Comprehensive Introduction. Wiley, 2010.
- S. Haykin, Adaptive Filter Theory, Fourth edition, Prentice Hall, 2002.
- W. Liu, P. Pokharel, J. C. Principe. The kernel least mean square algorithm, IEEE Transactions on Signal Processing, volume 56, issue 2, pages 543-554, 2008.
- J. Kivinen, A. Smola and R. C. Williamson. Online learning with kernels, IEEE Transactions on Signal Processing, volume 52, issue 8, pages 2165-2176, 2004.
- W. Liu, J. C. Principe. The kernel affine projection algorithms, EURASIP Journal on Advances in Signal Processing, 2008.
- Y. Engel, S. Mannor and R. Meir. The kernel recursive least-squares algorithm, IEEE Transactions on Signal Processing, volume 52, issue 8, pages 2275-2285, 2004.
- W. Liu, J. C. Principe. Extended recursive least squares in RKHS, Proc. First Workshop on Cognitive Signal Processing, Santorini, Greece, 2008.
- L. Ralaivola, F. d'Alche-Buc. Time series filtering, smoothing and learning using the kernel Kalman filter, Proceedings. 2005 IEEE International Joint Conference on Neural Networks, pages 1449-1454, 2005.